fbc7f114
 tangwang
docs tangwang
docs
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
|
# 电商个性化推荐 SaaS 技术方案:数据获取与打通
## 1. 引言
本技术方案旨在阐述如何构建一个电商个性化推荐 SaaS 平台,重点聚焦于**全渠道数据获取、数据整合与打通**的核心技术实现。我们将借鉴 Nosto 等行业领先者的实践经验,结合当前主流技术栈,设计一套可扩展、高可用且符合数据隐私规范的系统架构。
## 2. 核心架构概览
个性化推荐 SaaS 平台的核心在于高效地收集、整合和处理来自不同渠道的用户行为数据与业务数据,并在此基础上构建统一的客户视图,为个性化推荐提供坚实的数据基础。以下是整体架构的概览图:
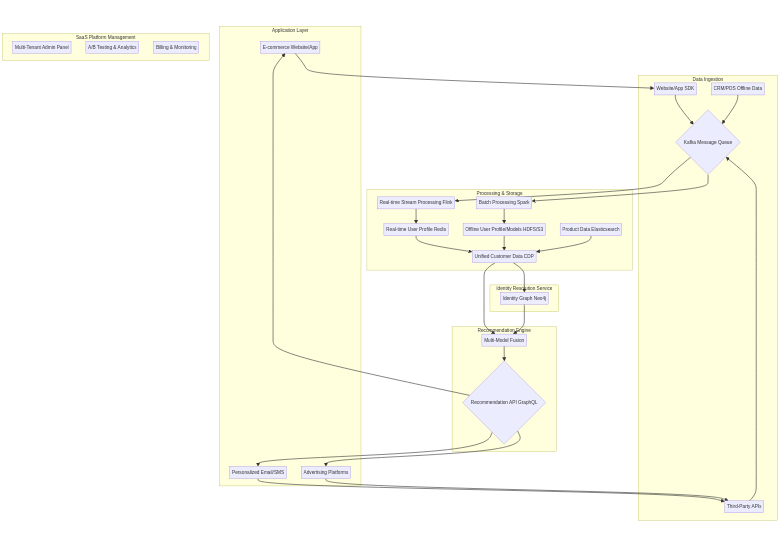
## 3. 数据采集层:多源异构数据接入
数据采集是构建个性化推荐系统的第一步,也是最关键的一步。我们需要建立一套灵活、实时且可靠的数据采集机制,覆盖用户在电商旅程中的所有触点。
### 3.1 网站与移动应用行为数据采集
* **网站行为数据**:通过 **JavaScript SDK (Pixel)** 部署在电商网站前端,实时捕获用户的页面浏览、点击、加购、收藏、搜索、购买等行为。每个会话通过 `session_id` 或 `cookie_id` 进行标识。SDK 应支持异步加载,避免影响网站性能。
* **移动应用数据**:通过 **原生 SDK (iOS/Android)** 嵌入到移动应用中,采集与网站类似的用户行为数据。为实现跨设备追踪,移动 SDK 需与网站 SDK 共享用户 ID 机制。
**技术实现建议**:
* **消息队列**:采用 **Apache Kafka** 或 **RabbitMQ** 作为数据接入层,处理每秒数十万级别的实时事件流,确保数据不丢失、高吞吐量和低延迟 [1]。
* **数据格式**:统一采用 JSON 或 Protobuf 格式封装事件数据,包含 `event_type`、`user_id` (如果已知)、`anonymous_id`、`session_id`、`product_id`、`timestamp`、`device_info`、`geo_location` 等关键字段。
### 3.2 第三方平台数据接入
电商生态系统往往涉及多个外部平台,如社交媒体、广告平台、营销自动化工具等。通过 **Server-to-Server (S2S) API 集成** 是实现这些数据打通的关键,而非简单的客户端 SDK 采集或数据爬取。
* **社交媒体平台 (如 Meta/Facebook/Instagram)**:
* **OAuth 2.0 授权**:商家通过 OAuth 2.0 流程授权 SaaS 平台访问其 Meta 商业账户的 API 权限(如 `ads_management`, `ads_read`, `business_management`)。SaaS 平台获取长期访问令牌,用于后续的 API 调用 [2]。
* **Meta Conversions API (CAPI)**:SaaS 平台作为 Meta 的合作伙伴,通过 CAPI 将服务器端的转化事件(如购买、加购)直接发送给 Meta,弥补浏览器端 Pixel 追踪的不足,提高广告归因的准确性 [3]。这需要服务器到服务器的直接通信,而非通过用户浏览器。
* **广告平台 (如 Google Ads)**:
* **Google Ads API**:通过 API 获取广告投放数据、点击数据和转化数据。同样,需要商家授权 SaaS 平台访问其 Google Ads 账户 [4]。
* **Server-Side Tagging**:利用 Google Tag Manager (GTM) 的服务器端容器,将网站事件数据发送到 SaaS 平台的服务器,再由 SaaS 平台转发给 Google Ads,实现更可靠的追踪 [5]。
* **其他第三方平台 (如 Shopify Flow, LoyaltyLion, Yotpo)**:
* **Webhook 机制**:通过配置 Webhook,当第三方平台发生特定事件(如订单状态变更、会员积分变动、用户评论)时,实时将数据推送到 SaaS 平台的数据接收接口。
* **API 定时拉取**:对于不支持 Webhook 或需要批量同步的数据,通过定时任务调用第三方平台的 API 进行数据拉取。
**关键技术特征**:
* **双向 S2S 架构**:数据直接在商家服务器 → SaaS 平台服务器 → 外部平台服务器之间传输,无需中间人。
* **实时 + 批量混合**:支持实时事件转发(毫秒级)和定时批量同步(小时级)。
* **去重机制**:通过 `event_id` 和 `session_id` 避免客户端与服务端事件重复。
### 3.3 离线数据导入
* **CRM/POS 系统数据**:支持通过 SFTP 文件传输(CSV/JSON 格式)或实时 API 推送的方式,批量导入客户关系管理 (CRM) 系统和销售终端 (POS) 系统中的客户信息、订单历史、会员等级等数据。
* **CDP 集成**:支持 Segment、mParticle 等标准 CDP 的数据格式,方便商家将已有的 CDP 数据导入。
## 4. 身份识别与统一:构建 Identity Graph
全渠道数据整合的核心挑战之一是**用户身份识别与统一**。不同渠道的用户行为可能由同一个用户产生,但却拥有不同的标识符(如网站 Cookie ID、App 设备 ID、邮箱、手机号)。构建 **Identity Graph (身份图谱)** 是解决这一问题的关键。
### 4.1 身份图谱的核心逻辑
Identity Graph 旨在将一个用户的不同标识符关联起来,形成一个统一的客户视图 (Customer 360)。
| 标识符类型 | 描述 | 示例 |
| :--------------- | :--------------------------------------- | :--------------------------------------- |
| **匿名 ID** | 设备级标识,如 `2c.cId cookie` 值、设备指纹 | `cookie_value_xyz`、`web_1920x1080_chrome_mac` |
| **已知 ID** | 登录用户标识,如 `user_id`、邮箱、手机号 | `user_12345`、`user@example.com`、`+86-138****1234` |
| **关联关系** | 不同 ID 之间的连接关系 | `user_12345` 关联 `cookie_value_xyz` |
### 4.2 关键技术与匹配策略
* **确定性匹配 (Deterministic Matching)**:
* 基于强标识符进行匹配,准确率高。例如,用户登录时,将当前匿名会话的 `anonymous_id` 与其 `user_id` 进行关联。
* 其他确定性匹配场景包括邮箱订阅、手机号绑定、会员卡号等。
* **技术实现**:维护一个 ID 映射表,存储 `anonymous_id` 到 `user_id` 的映射关系,并支持实时更新。
* **概率性匹配 (Probabilistic Matching)**:
* 当缺乏强标识符时,通过算法推测不同匿名行为是否属于同一用户。例如,基于设备指纹 (Device Fingerprint)、行为模式、IP 地址、地理位置等信息进行匹配 [6]。
* **设备指纹**:结合浏览器类型、操作系统、屏幕分辨率、插件列表、字体等信息生成设备的唯一标识。可集成第三方库如 FingerprintJS。
* **行为模式**:分析用户在不同设备上的浏览路径、购买偏好、时间规律等,通过机器学习模型计算相似度。
* **技术实现**:
* **图数据库 (如 Neo4j)**:存储 ID 之间的关联关系,方便进行复杂的关系查询和图算法分析,发现潜在的概率性匹配 [7]。
* **机器学习模型**:训练分类模型(如逻辑回归、随机森林)来预测不同匿名 ID 属于同一用户的概率。
* **实时 ID 合并**:当用户登录或提供新的身份信息时,系统应立即合并其历史匿名行为数据,更新用户画像,确保推荐的实时性和准确性。
## 5. 数据整合与处理:统一客户数据资产 (CDP)
将采集到的多源数据和统一身份后的数据进行整合、清洗、转换,最终形成一个统一的客户数据平台 (Customer Data Platform, CDP),是为个性化推荐提供数据支撑的关键。
### 5.1 Lambda 架构与实时流处理
为满足“每秒数十万次实时请求”和毫秒级延迟更新用户画像的需求,系统应采用 **Lambda 架构**,结合实时层和批处理层 [8]。
* **实时层**:
* **技术栈**:**Apache Flink** 或 **Spark Streaming**。
* **功能**:处理 Kafka 消息队列中的实时行为流,进行数据清洗、格式转换、实时聚合、特征提取,并毫秒级延迟更新用户画像。
* **输出**:实时更新的用户画像数据存储到 Redis 等低延迟存储中。
* **批处理层**:
* **技术栈**:**Apache Spark** 或 **Hadoop MapReduce**。
* **功能**:每日或定期处理全量历史数据,进行更复杂的离线计算,如用户聚类、商品相似度计算、模型训练、数据修正和补充实时计算结果。
* **输出**:离线计算结果存储到 HDFS/S3 等分布式存储,并同步到 CDP。
### 5.2 CDP 核心数据模型
CDP 旨在构建一个全面的客户 360 度视图,包含以下核心数据域:
| 数据域 | 存储内容 | 典型技术组件 |
| :----------- | :--------------------------------------- | :----------------------- |
| **行为事件** | 点击、浏览、加购、购买等原始事件 | Kafka + Flink |
| **用户属性** | 人口统计、会员等级、RFM 标签、偏好向量 | Redis + PostgreSQL |
| **产品目录** | SKU、价格、库存、类目、标签等商品元数据 | Elasticsearch |
| **场景上下文** | 时间、设备、地理位置、来源渠道 | MongoDB |
| **关系网络** | 用户相似度、商品共现、ID 关联关系 | Neo4j 图数据库 |
### 5.3 数据存储策略
根据数据的访问频率和时效性,采用分层存储策略:
* **热数据**:用户最近的活跃行为(如最近 50 个行为)存储在 **Redis** 集群中,设置较短的 TTL (Time-To-Live),支持毫秒级快速读写。
* **温数据**:近 30 天的行为数据存储在 **Cassandra** 或 **ClickHouse** 等分布式列式数据库中,支持快速查询和聚合分析。
* **冷数据**:全量历史数据存储在 **S3/HDFS** 等对象存储或分布式文件系统中,用于离线训练和长期归档。
## 6. SaaS 平台化设计:多租户与数据安全
作为一个 SaaS 平台,多租户架构设计至关重要,需要确保不同商家之间的数据隔离、资源隔离和安全性。
### 6.1 多租户隔离策略
* **数据隔离**:
* **独立数据库 (Database-per-Tenant)**:为每个商家分配独立的数据库实例,提供最强的数据隔离性,但成本较高,管理复杂 [9]。
* **独立 Schema (Schema-per-Tenant)**:在共享数据库中为每个商家创建独立的 Schema,数据隔离性良好,成本适中 [9]。
* **共享数据库,通过 Tenant ID 隔离 (Shared Database with Tenant ID)**:所有商家数据存储在同一个数据库中,通过在每张表中添加 `tenant_id` 字段进行逻辑隔离。实现简单,成本最低,但需要严格的应用程序逻辑控制数据访问 [9]。
* **建议**:对于核心敏感数据(如用户画像、行为事件),可采用独立 Schema 或独立数据库;对于公共数据(如商品目录模板),可采用共享数据库加 `tenant_id` 隔离。在 Kafka 消息队列中,可为每个租户创建独立 Topic 或使用 `tenant_id` 作为消息 Key 进行分区。
* **资源隔离**:
* **Kubernetes 命名空间 (Namespace)**:在 Kubernetes 集群中为每个商家创建独立的命名空间,通过资源配额 (Resource Quotas) 限制 CPU、内存等资源使用,防止“邻居干扰”问题 [10]。
* **容器化部署**:将各个服务(数据采集、流处理、API 服务等)容器化,通过 Docker 和 Kubernetes 进行部署和管理。
* **API 隔离**:为每个商家提供独立的 `accountID` 和 API Key,确保 API 调用的安全性和隔离性。
### 6.2 数据安全与合规
* **数据加密**:所有敏感数据(如用户 PII、支付信息)在传输和存储过程中必须进行加密。使用 TLS/SSL 保护数据传输,使用 AES-256 等算法加密静态数据。
* **访问控制**:实施严格的基于角色的访问控制 (RBAC),确保只有授权用户才能访问特定数据和功能。
* **隐私合规**:
* **GDPR (通用数据保护条例)** 和 **CCPA (加州消费者隐私法案)**:确保数据采集、存储、处理和共享符合 GDPR 和 CCPA 等隐私法规的要求 [11]。
* **用户数据删除**:提供用户数据删除功能,支持用户行使“被遗忘权”。
* **数据最小化**:只收集和存储必要的、与业务目的相关的数据。
* **透明度**:向用户清晰说明数据收集和使用政策。
## 7. 实施路线图 (数据获取与打通阶段)
### 7.1 第一阶段:MVP (数据采集与身份识别)
* **基础设施搭建**:
* 消息队列:Kafka (3 节点集群)
* 流处理:Flink on Kubernetes
* 缓存:Redis Cluster (6 节点)
* 数据库:PostgreSQL (用户数据) + Elasticsearch (商品目录)
* API 网关:Kong/AWS API Gateway
* **核心功能实现**:
* **JavaScript SDK**:页面埋点、Cookie 管理、行为上报。
* **身份服务**:匿名 ID 生成、登录态关联、ID 映射表。
* **数据接收 API**:接收网站/APP SDK 上报的事件数据,写入 Kafka。
* **管理后台**:商家注册、API Key 管理、数据源配置。
* **数据模型设计**:
* `user_events` 表:存储原始用户行为事件。
* `user_identity_map` 表:存储匿名 ID 与已知 ID 的映射关系。
### 7.2 第二阶段:全渠道整合与 CDP 建设
* **扩展数据源**:
* **移动端 SDK**:iOS/Android 埋点采集。
* **CRM 对接**:Salesforce、HubSpot API 集成。
* **营销平台对接**:Klavyio、Mailchimp 获取邮件互动数据。
* **广告平台 S2S 集成**:Meta CAPI、Google Ads API/Server-Side Tagging。
* **增强身份识别**:
* **设备指纹库**:集成 FingerprintJS/Thumbor。
* **图谱算法**:使用 Neo4j 存储 ID 关联关系,实现概率匹配。
* **实时 ID 合并引擎**:确保用户身份实时统一。
* **CDP 建设**:
* **实时用户画像**:Flink 处理实时流,更新 Redis 中的用户画像。
* **统一客户数据模型**:设计并实现 CDP 核心数据模型,整合行为、属性、产品、场景数据。
* **数据存储分层**:Redis (热数据)、Cassandra (温数据)、S3/HDFS (冷数据)。
## 8. 关键技术挑战与应对方案
| 挑战 | 应对方案 |
| :------------- | :------------------------------------------- |
| **数据延迟** | Flink 实时流处理,Redis 缓存热数据,P99 延迟 < 200ms |
| **ID 关联准确率** | 确定性 + 概率性匹配,持续学习优化,初期 95% 准确率,通过反馈数据迭代 |
| **商品库同步** | 支持增量同步 + 全量校对,延迟 < 1 分钟 |
| **多租户数据隔离** | 独立 Schema/数据库 + Tenant ID 逻辑隔离,Kubernetes 资源配额 |
| **数据安全合规** | 数据加密、RBAC、GDPR/CCPA 合规,支持用户数据删除 |
| **系统稳定性** | 熔断、限流、降级三件套,多云部署,99.9% 可用性 |
## 9. 总结
本方案详细阐述了构建电商个性化推荐 SaaS 平台在**数据获取与打通**方面的技术实现路径。通过建立强大的数据采集层、智能的身份识别服务、高效的数据整合处理机制以及安全的多租户架构,我们将能够为商家提供一个稳定、可靠且功能强大的个性化推荐基础平台,助力其实现业务增长。
## 10. 参考文献
[1] Apache Kafka. [https://kafka.apache.org/](https://kafka.apache.org/)
[2] Meta for Developers - OAuth 2.0. [https://developers.facebook.com/docs/facebook-login/guides/advanced/manual-flow/](https://developers.facebook.com/docs/facebook-login/guides/advanced/manual-flow/)
[3] Meta for Developers - Conversions API. [https://developers.facebook.com/docs/marketing-api/conversions-api/](https://developers.facebook.com/docs/marketing-api/conversions-api/)
[4] Google Ads API. [https://developers.google.com/google-ads/api/docs/start](https://developers.google.com/google-ads/api/docs/start)
[5] Google Tag Manager - Server-side tagging. [https://developers.google.com/tag-platform/tag-manager/server-side/intro](https://developers.google.com/tag-platform/tag-manager/server-side/intro)
[6] Identity Resolution: Unifying User Profiles. [https://www.okta.com/identity-101/identity-resolution/](https://www.okta.com/identity-101/identity-resolution/)
[7] Neo4j Graph Database. [https://neo4j.com/](https://neo4j.com/)
[8] Lambda Architecture. [https://en.wikipedia.org/wiki/Lambda_architecture](https://en.wikipedia.org/wiki/Lambda_architecture)
[9] Data Isolation and Sharding Architectures for Multi-Tenant Systems. [https://medium.com/@justhamade/data-isolation-and-sharding-architectures-for-multi-tenant-systems-20584ae2bc31](https://medium.com/@justhamade/data-isolation-and-sharding-architectures-for-multi-tenant-systems-20584ae2bc31)
[10] Kubernetes Namespaces. [https://kubernetes.io/docs/concepts/overview/working-with-objects/namespaces/](https://kubernetes.io/docs/concepts/overview/working-with-objects/namespaces/)
[11] GDPR for SaaS: 8 Steps to Ensure Compliance. [https://www.cookieyes.com/blog/gdpr-for-saas/](https://www.cookieyes.com/blog/gdpr-for-saas/)
|